PHP-FPM broken pipe on AWS Lambda: what I tried, what worked, and what I still don't know
There are some nasty bugs that are open for a long time. Other engineers have had a shot at it and couldn't diagnose it. Sometimes, you have to live with an unconventional, yet effective fix. This post is about one such platform/infra-level fix.
Broken pipes almost always require me to call the plumber (only after my partner reminds me to do it for the 10th time, of course), but when I started on the Lemon Squeezy team at Stripe, I was tasked with a different kind of broken pipe error.
Some background first
The app was a Laravel app running on AWS Lambda using Bref/Serverless. AWS Lambda's serverless functions aren't built for PHP traditionally. Bref provides you with a way to run PHP on AWS Lambda.
In a typical Laravel environment, your Apache or Nginx server will hand off the web request to the PHP-FPM worker through a Unix socket (just a fancy word for a file living in memory), and the PHP-FPM worker hands it off to Laravel. In the case of Bref, Bref provides a PHP-FPM worker and hands the request to it. The job of the PHP worker is to create the socket and let Bref write requests to it. Think of the socket like an open pipe. Bref passes the requests from the top, and a worker consumes them from the bottom.
While the product was broadly stable, our availability SLO attainment suffered. For context, availability is the percentage of successful requests. We define attainment using 5-minute windows over a 30-day period (12 per hour, 288 per day, so 8,640 total buckets); our goal is for 99% of these windows to have an availability rate above 99.9%. The attainment was dropping week after week, and it fell to 41%.
I was tasked with bringing the attainment to 99%. The key contributor was this error: Error communicating with PHP-FPM to read the HTTP response. Bref will restart PHP-FPM now. Original exception message: WriteFailedException: Failed to write request to socket [broken pipe];
The error pattern on a single Lambda instance:
- Request N completes normally (e.g., 220ms)
- Request N+1 arrives ~6ms later
- WriteFailedException immediately — the FPM socket is already dead
- Bref restarts FPM, request N+2 works
From a user's perspective, this surfaced as random internal server errors. Nobody had been able to pin it down for over a year. There were multiple investigations and theories, including fixing long-running processes and DB queries causing process deaths, but the conclusion was upgrading to PHP 8.4.
The root cause wasn't quite ascertained; however, Bref was more compatible with PHP 8.4 than 8.1, and the investigation had recommended that the improved compatibility would fix it. Too bad, it didn't. I tried a few things before working on the PHP upgrade.
A Red Herring
"Bref will restart PHP-FPM now" — this made me assume that the PHP-FPM worker was dying since Bref was restarting, and the next request always succeeded.
This was one of those issues where there was absolutely no clue as to why it was happening. Any theory without proof is a conspiracy theory is one of the first principles I believe in. But I also like quick wins when production is on fire over a fix that will take weeks.
There was a similar issue that had been open on the repo for 2 years, and it recommended a bunch of solutions and debugging. The following list of trials took anywhere between an hour and 3 hours to write, deploy, and test. In a typical staff engineer's day, with other work stream responsibilities, meetings, and context switches, these trial-and-error attempts add up.
- Is the Lambda execution going out of memory? No, it was well within 300 MB.
- Is JIT causing a segmentation fault? Fair theory — JIT in PHP was known to cause segmentation faults in PHP 8.1. I had heard from a fellow dev, but the version of Bref we were using had JIT disabled by default.
- Sentry tracing can interfere with the PHP-FPM worker; disable Sentry to see if the errors go away. Didn't help.
- Lambda cold starts are causing the PHP-FPM worker to die. Nope, we had very few cold starts.
- Is the stderr log_limit of 8K causing a problem? No, the longest log we had was well under 2K.
- Is the PHP-FPM child worker dying? Nope, no SIGPIPE in our logs indicating child worker dying.
- We migrated from Redis to Valkey a few months prior, and around the same time, the number of PHP-FPM Bref errors increased. Could that have caused an issue somehow? No, there are no Redis or Valkey related errors in our logs.
- Are large responses for some requests the reason? No correlation between response size and errors.
After exhausting some of the quick wins from above, I decided to go ahead with our PHP version upgrade from 8.1 to 8.4 (the PHP upgrade project perhaps requires a mini blog post of its own), spanning 3 weeks, where I touched 2,500+ files.
There were zero regressions from an upgrade standpoint, but it was a bit of an "operation successful, but the patient is dead" situation. The PHP upgrade didn't solve the issue as the previous investigations had hoped — the improved compatibility between Bref and PHP didn't solve the issue.
A Deep Dive into the Bref vendor code and an 'aha' moment
Having exhausted all options, I was convinced that the problem was with the third-party vendor code. I decided to open an issue on the repo as well.
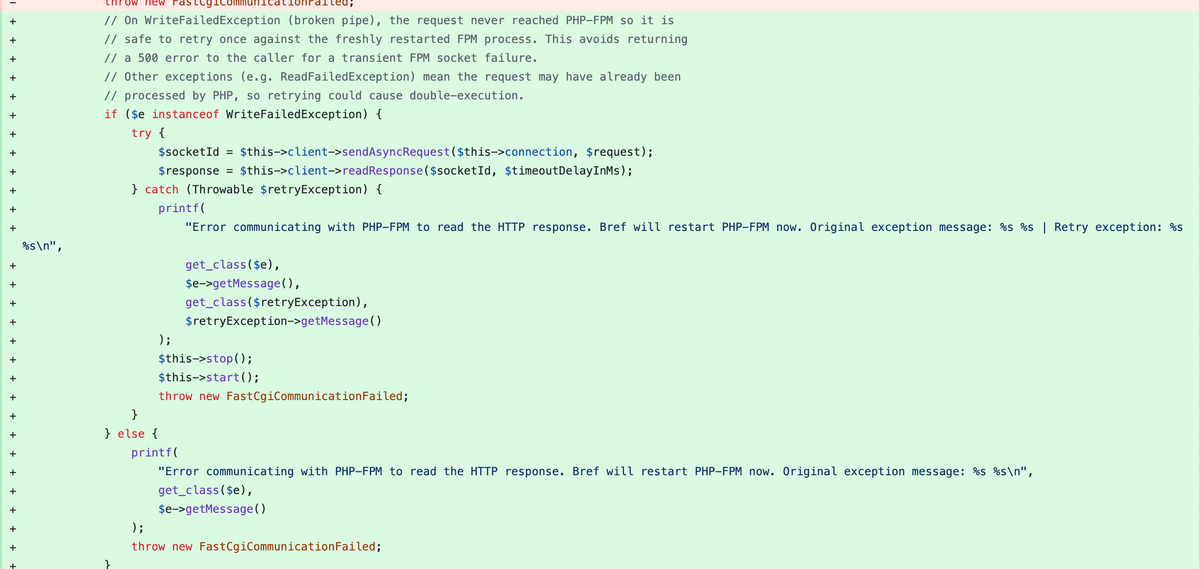
As I was reading through the code of the Bref repository, I had a sudden 'aha' moment. Request N completes normally, Request N+1 fails with the broken pipe error, but when Bref restarts the master PHP-FPM worker, request N+2 succeeds.
What if Bref checked if the PHP-FPM worker is dead before sending the request to it and proactively restarted the worker before sending the request? That way, no request has to fail. The only problem is this was a third-party OSS package, and I needed to patch it (Pro-tip: cweagans/composer-patches, is a beautiful package you could use to run patched versions of your Composer package. It works in a brilliantly simple way).
Since I had decided to get my hands dirty with the vendor code, I thought I would add some logging first. Why is the PHP-FPM worker dying? I added some logs to get some answers. Surprise, surprise — the PHP-FPM worker wasn't dying.
I was heartbroken. All our investigation and my 'great' solution to just preemptively restart the PHP-FPM worker was just proven moot. Another dead end, I thought, until I decided to dive deeper into the code.
Victory, finally.
It was proven that restarting the PHP-FPM master fixes the issue for the next request. So I thought — why not 'safely' retry the request after restarting the PHP-FPM worker?
Conventional as I am, I also like to be brave and try fixes that alleviate the pain points for the end user. At this point, the decision was straightforward. I had been at this for 4 weeks, the bug had been open for a year, and our SLO was still degrading. The root cause lived somewhere inside AWS Lambda's runtime — a black box we have no visibility into. I knew the retry fix would work. So I shipped it. Sometimes the right call is not the perfect solution; it's the solution that stops the bleeding and lets you move on. The root cause can wait for the Bref maintainers; our users couldn't.
I patched this fix up and deployed it. The availability instantly jumped from 41% to 99.99%. I have also opened a PR upstream to get it accepted. I still have to conclusively prove why the broken pipe errors are happening. I was overjoyed at reaching 99.99% availability and completely getting rid of the 500 internal server errors.
We still don't know why the PHP-FPM workers aren't dying, but somehow the Unix socket is getting corrupted. There is no way to find out why — AWS Lambda instances can't be accessed, and rightly so.
I plan to try to get my fix accepted to the vendor repository in the coming months for the benefit of anyone facing the same issue as us, but for now, I am happy with our patched version of the fix.